この記事は、AWSアドベントカレンダー2022 の20日目の記事です。
AWS Fault Injection Simulator(FIS)は、 障害を挿入する実験をおこない、アプリケーションの回復性や信頼性を 確認、改善するためのマネージドサービスです。 いわゆるカオスエンジニアリングの実験をおこなうことができます。
2021年の3月にGAになったFISは、少しずつ対応する障害注入アクションの種類を増やしてきました。
私も今年の6月ぐらいにちょっといじっていたのですが、当時はKubernetesに対する障害にはほとんど対応していませんでした。
その直後の、7月に待望のEKSに対する障害注入アクションが追加されたのですが、
その実現方式は、k8sのカオスエンジニアリングツールとして有名な ChaosMesh と Litmus を呼び出すことができるというものでした。
正直、当時は「そう来たか〜」と思ったものですが、実際に動かしてみる機会がなかったので今回実際に触ってみようと思います。
環境のセットアップ
今回は、EKSに対してFISとChaosMeshを連携させて障害の注入を試してみます。 カオスエンジニアリングを試してみるには、アプリケーションが必要です。 マイクロサービスのデモアプリケーションとして有名なものの一つであるSock Shop を使います。 Sock Shopは主にWeaveworksがメンテナンスしているマイクロサービスのデモアプリで、 アプリケーションだけでなくモニタリングや負荷がけの設定も用意されているので簡単に試すことが可能です。
EKSのセットアップ
EKSは普通にセットアップするので詳細は割愛します。
ただし普段NetworkPolicyが欲しいケースがあるので、デフォルトのCNIである aws-cni ではなくて Calico を使いました。
あまりEKS + Calicoは相性がそこまで良いとも言えず、k8sのwebhook用のPodに対して .spec.hostNetwork: true の設定を入れる必要があったり、
なにかと面倒なので無理にやらなくてもよいと思います。
ただし、aws-vpcをデフォルトのまま利用すると、1ノードあたりで起動できるPodの数が非常に少なく、 今回のようにいろいろなものをデプロイしたい場合に非常に多くのノードが必要になってしまうので、以下の設定を入れることをお勧めします。
https://docs.aws.amazon.com/ja_jp/eks/latest/userguide/cni-increase-ip-addresses.html
EKSにCalicoを入れるには、Calicoの公式ドキュメントを参照してください。 AWS側のドキュメントの手順でやっても、(少なくとも日本語版は)うまく設定できなかったのでCalico側を見ることをお勧めします。
https://projectcalico.docs.tigera.io/getting-started/kubernetes/managed-public-cloud/eks
Sock Shopのデプロイ
次に、Sock Shopをデプロイします。
なお、Sock ShopのアプリケーションのDeployment定義において、
mongo dbが新しくなりすぎていて、アプリケーション側(DBクライアント側)と互換性が無くなり、エラーが出てしまいます。
下記issueの通り、デプロイ前に手動で修正して、バージョンを指定してあげましょう。
具体的には、イメージ指定の箇所で、 image: mongo とlatest指定になっているのを image: mongo:5.0.11 とバージョン指定します。
https://github.com/microservices-demo/microservices-demo/issues/900
$ git clone https://github.com/microservices-demo/microservices-demo
$ cd microservices-demo/deploy/kubernetes
# 上記mongoのバージョン設定をおこなう
$ vi manifests/03-carts-db-dep.yaml
$ vi manifests/13-orders-db-dep.yaml
# アプリケーションのデプロイ
$ kubectl apply -f manifests
デプロイが完了したら、NodePortでサービスが公開されているので、アクセスできることを確認しましょう。 front-endがTCP30001ポートで公開されているので、EC2インスタンスの30001ポートにアクセスすると、 Sock Shopのアプリケーションが動作しているのを確認できると思います。
$ kubectl get svc -n sock-shop
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
carts ClusterIP 172.20.216.10 <none> 80/TCP 37h
carts-db ClusterIP 172.20.124.238 <none> 27017/TCP 37h
catalogue ClusterIP 172.20.97.161 <none> 80/TCP 37h
catalogue-db ClusterIP 172.20.160.217 <none> 3306/TCP 37h
front-end NodePort 172.20.143.5 <none> 80:30001/TCP 37h
orders ClusterIP 172.20.240.155 <none> 80/TCP 37h
orders-db ClusterIP 172.20.35.101 <none> 27017/TCP 37h
payment ClusterIP 172.20.117.186 <none> 80/TCP 37h
queue-master ClusterIP 172.20.29.104 <none> 80/TCP 37h
rabbitmq ClusterIP 172.20.174.80 <none> 5672/TCP,9090/TCP 37h
session-db ClusterIP 172.20.6.130 <none> 6379/TCP 37h
shipping ClusterIP 172.20.199.13 <none> 80/TCP 37h
user ClusterIP 172.20.195.229 <none> 80/TCP 37h
user-db ClusterIP 172.20.38.144 <none> 27017/TCP 37h
監視と負荷ツールのデプロイ
動いたことを確認したら、続けて監視用の設定と負荷掛け用の設定を投入します。 監視用の設定は、Grafanaのダッシュボード設定用のyamlファイルがGrafanaがデプロイされていることを前提として作られているので、 まとめてデプロイすることができません。同梱されているREADME.mdを見ながらひとつずつデプロイしていきます。
$ pwd
path/to/microservices-demo/deploy/kubernetes/
$ cd manifests-monitoring/
# 監視設定のデプロイ
$ kubectl create -f 00-monitoring-ns.yaml
$ kubectl apply $(ls *-prometheus-*.yaml | awk ' { print " -f " $1 } ')
$ kubectl apply $(ls *-grafana-*.yaml | awk ' { print " -f " $1 }' | grep -v grafana-import)
$ kubectl apply -f 23-grafana-import-dash-batch.yaml
# 負荷掛け設定のデプロイ
$ cd ..
$ kubectl apply -f manifests-loadtest/loadtest-dep.yaml
負荷掛けのアプリケーションは、 Locust を使った負荷設定がされており、デプロイするだけで継続的に負荷を掛けることができます。
ログを見ればその内容も確認することができます。
$ kubectl -n loadtest get pod
(前略)
NAME READY STATUS RESTARTS AGE
load-test-7b8dbc789-sd2jt 1/1 Running 0 4m
load-test-7b8dbc789-tncrp 1/1 Running 0 3m59s
$ kubectl -n loadtest logs load-test-7b8dbc789-sd2jt
[2022-12-18 01:45:29,751] load-test-7b8dbc789-ndm4d/INFO/locust.main: Starting Locust 0.7.5
[2022-12-18 01:45:29,752] load-test-7b8dbc789-ndm4d/INFO/locust.runners: Hatching and swarming 5 clients at the rate 5 clients/s...
Name # reqs # fails Avg Min Max | Median req/s
--------------------------------------------------------------------------------------------------------------------------------------------
--------------------------------------------------------------------------------------------------------------------------------------------
Total 0 0(0.00%) 0.00
[2022-12-18 01:45:30,758] load-test-7b8dbc789-ndm4d/INFO/locust.runners: All locusts hatched: Web: 5
[2022-12-18 01:45:30,758] load-test-7b8dbc789-ndm4d/INFO/locust.runners: Resetting stats
Name # reqs # fails Avg Min Max | Median req/s
--------------------------------------------------------------------------------------------------------------------------------------------
GET / 10 0(0.00%) 39 7 91 | 33 0.00
GET /basket.html 11 0(0.00%) 12 4 53 | 8 0.00
DELETE /cart
(後略)
また、監視についてもGrafanaがやはりNodePortで公開されているので、 ポートを確認してアクセスします。
$ kubectl -n monitoring get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
grafana NodePort 172.20.254.180 <none> 80:31300/TCP 36h
kube-state-metrics ClusterIP None <none> 8080/TCP,8081/TCP 36h
node-exporter ClusterIP None <none> 9100/TCP 36h
prometheus NodePort 172.20.34.79 <none> 9090:31090/TCP 36h
TCP31300にアクセスすると、Grafanaにアクセスすることができます。
ユーザ認証がありますが、デフォルトのユーザ/パスワードは admin/admin でログインすることができます。
GrafanaでPodのリソース使用状況や、各サービスの処理能力、レイテンシなどを確認することが可能です。
なかなか長くなりましたがアプリケーションの環境セットアップは以上となります。
ChaosMeshのセットアップ
つづけて、ChaosMeshをセットアップしていきます。
ChaosMeshのインストール
まずはEKSにChaosMeshをインストールします。
インストール方法として、シェルスクリプトを実行するだけのクイックスタートとHelmの方法の2つが用意されていますが、
クイックスタートはコンテナランタイムがDockerであることを前提としています。
現代のEKSはコンテナランタイムが containerd になっており、いざ実験開始してみたら動かず再インストールするはめにあうので、
はじめからhelmを使ってインストールしましょう(一敗)。
https://chaos-mesh.org/docs/production-installation-using-helm/
基本的に手順通りやっていけばインストールは完了します。
$ helm repo add chaos-mesh https://charts.chaos-mesh.org
$ helm search repo chaos-mesh
$ kubectl create ns chaos-mesh
$ helm install chaos-mesh chaos-mesh/chaos-mesh -n=chaos-mesh --set chaosDaemon.runtime=containerd --set chaosDaemon.socketPath=/run/containerd/containerd.sock --set controllerManager.hostNetwork=true --version 2.5.0
なお、最後のhelmコマンドの引数に含まれる --set controllerManager.hostNetwork=true ですが、
これはCNIをCalicoにしているために追加しています。
aws-cniを利用している場合は特にこの引数は不要です。
ChaosMeshにもダッシュボードがありますが、今回は利用しないので省略します。
ChaosMeshを動かしてみる
ChaosMeshでは障害ごとに CRD(Custom Resource Definision) が定義されており、それらのカスタムリソースを作成することで障害を注入することができます。
たとえば、以下のようなyaml定義をpod-kill.yamlという名前で作成し、 これをデプロイするとSelectorにマッチするPodを終了させることができます。
apiVersion: chaos-mesh.org/v1alpha1
kind: PodChaos
metadata:
name: pod-kill
spec:
action: pod-kill
mode: one
selector:
namespaces:
- sock-shop
labelSelectors:
name: 'carts'
これをデプロイすると、PodChaosのカスタムリソースが作成されると同時に、
sock-shop 名前空間の、 name=carts のラベルを持つPodが終了して再起動したことが確認できます。
確認が終わったらPodChaosのカスタムリソースは削除しておきましょう。
$ kubectl get PodChaos
No resources found in default namespace.
$ kubectl apply -f pod-kill.yaml
podchaos.chaos-mesh.org/pod-kill created
$ kubectl get pod -n sock-shop
NAME READY STATUS RESTARTS AGE LABELS
carts-7bbf9dc945-h6p9d 1/1 Running 0 5s name=carts
carts-db-5dfd9c6594-6gc7h 1/1 Running 0 48m name=carts-db
catalogue-6479dbb5bd-qrd6b 1/1 Running 0 33h name=catalogue
catalogue-db-6b55d8cdb7-mbbxf 1/1 Running 0 48m name=catalogue-db
front-end-7f5c844b4c-kqzvx 1/1 Running 0 48m name=front-end
orders-74f65597c5-hcq4p 1/1 Running 0 33h name=orders
orders-db-74698dffd-t8qt7 1/1 Running 0 48m name=orders-db
payment-c7df5b49-5qnxh 1/1 Running 0 33h name=payment
queue-master-9fc44d68d-wdxl5 1/1 Running 0 33h name=queue-master
rabbitmq-6576689cc9-q2cjh 2/2 Running 0 48m name=rabbitmq
session-db-695f7fd48f-lqgxb 1/1 Running 0 48m name=session-db
shipping-79c568cddc-9kpzs 1/1 Running 0 48m name=shipping
user-79dddf5cc9-8vhg9 1/1 Running 0 33h name=user
user-db-b8dfb847c-2xgsv 1/1 Running 0 48m name=user-db
$ kubectl get PodChaos
NAME AGE
pod-kill 11s
$ kubectl delete PodChaos pod-kill
podchaos.chaos-mesh.org "pod-kill" deleted
$
IAMロール、ClusterRoleの設定
次に、FISの実験実行用のIAMロールを作成し、そのIAMロールでChaosMeshの障害を注入できるようにします。 この後出てきますが、FISでChaosMeshと連携する際は、その実験用のロールがkubernetesのAPIを呼ぶだけです。 そのため、kubernetesのAPIを呼び出せるようにIAMロールとClusterRoleの連携の設定をおこないます。
IAMロールの作成
まずは、FISの連携用のロールを作ります。マネジメントコンソールでうまく作れなかったので、 ドキュメントに従い、aws cliを使って作成します。
https://docs.aws.amazon.com/ja_jp/fis/latest/userguide/getting-started-iam-service-role.html
$ echo "{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": [
"fis.amazonaws.com"
]
},
"Action": "sts:AssumeRole"
}
]
}" > fis-role-trust-policy.json
$ aws iam create-role --role-name my-fis-role --assume-role-policy-document file://fis-role-trust-policy.json
また、FISの実験ロールにはCloudWatch LogsのCreateLogDeliveryのアクションが必要なので、それを許可します。 私はVisual Editorを使って以下のようなインラインポリシーを作成してアタッチしています。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "logs:CreateLogDelivery",
"Resource": "*"
}
]
}
また、S3にログも保管したかったので、 AmazonS3FullAccess のポリシーもアタッチしています。
注意事項: 今回は簡略化のために権限は緩めに設定しています。 実際に利用する際は必要でない権限はつけないようにできるだけ絞りましょう。
ClusterRoleを作成する
次に、実験の際にカスタムリソースを作成する用のkubernetes側のRoleを作成します。
今回は、ドキュメントにあるChaosMesh管理者用の設定を元に定義を作りました。 こちらもIAMロールの権限同様に、実際に利用する際は強すぎる権限を与え過ぎないようによく検討しましょう。
以下のようにClusterRole、ClusterRoleBindingのyaml定義を作成し、デプロイすると
ChaosMeshの各種カスタムリソースを作成できるClusterRoleが作成され、
chaosmesh:manager グループに対してそれが割り当てられます。
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: chaosmesh-manager
rules:
- apiGroups: [""]
resources: ["pods", "namespaces"]
verbs: ["get", "watch", "list"]
- apiGroups:
- chaos-mesh.org
resources: [ "*" ]
verbs: ["get", "list", "watch", "create", "delete", "patch", "update"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
creationTimestamp: null
name: chaosmesh-manager-binding
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: chaosmesh-manager
subjects:
- kind: Group
name: chaosmesh:manager
IAMロールとClusterRoleを連携する
最後に、IAMロールとClusterRoleを連携し、
先ほど作成した IAMロール my-fis-role がkubernetesのAPIを呼び出してChaosMeshのカスタムリソースを操作できるようにします。
IAMロールがkubernetesの権限を得るためには、名前空間 kube-system にある ConfigMap のひとつ aws-auth を設定します。
kubectl -n kube-system edit configmap aws-auth を実行するとエディタが開かれるので、
例えば以下のように設定します。
apiVersion: v1
data:
mapRoles: |
- groups:
- system:bootstrappers
- system:nodes
rolearn: arn:aws:iam::123456789012:role/eks-sandbox-worker-node-role
username: system:node:{{EC2PrivateDNSName}}
- groups:
- chaosmesh:manager
rolearn: arn:aws:iam::123456789012:role/my-fis-role
username: chaosmesh-manager
kind: ConfigMap
metadata:
creationTimestamp: "2022-12-17T23:15:29Z"
name: aws-auth
namespace: kube-system
resourceVersion: "xxxxx"
uid: a0b0c0e0-abcd-1234-5678-1234567890ab
追加するのは以下の部分です。
- groups:
- chaosmesh:manager
rolearn: arn:aws:iam::123456789012:role/my-fis-role
username: chaosmesh-manager
groupのところにClusterRoleBindingsで入れたグループ名を、rolearnに作成したIAMロールのarnを入れます。 usernameは適当にいれてよいはずです。
これを保存すれば、FISからChaosMeshを呼び出す準備は完了です。
FISのセットアップ
最後にFISの実験テンプレートを作成します。
実験テンプレートの作成では実験の説明(名前)、1つ以上のアクション、アクションに対応したターゲット、 実験を実行するIAMロール、停止条件、ログを設定します。
今回はネットワークの遅延をシミュレートする NetworkChaos の注入だけをおこなう実験を作成します。
アクションの設定では以下のように設定をおこないます。
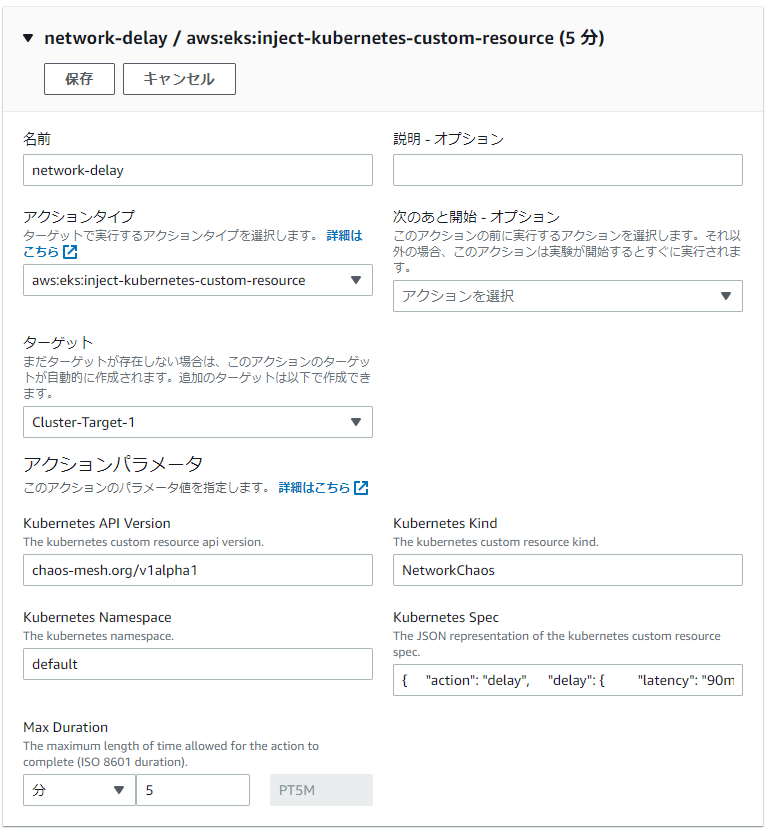
今回ChaosMeshとの連携をやってみて、一番信じがたかったのがこのアクションパラメータの部分でした。
なんと、カスタムリソースの設定を分解しながら入力ボックスに入れていくのです(しかもspec部分はjson形式)。 たしかに他のアクションもSSMドキュメントのパラメータを入力支援無しでjsonで入れるので 予想はつきましたが、ここはもうちょっと親切になって欲しいところです。
せめてIAMポリシーのエディタのようにjsonの入力支援がつくとか、それぐらいは実現してほしい。 1行のインプットボックスに対してjsonを設定するのは、なかなか大変でした。
さて、脱線しましたが、アクションパラメータにはそれぞれ以下のものを入力します。
- Kubernetes API Version
- カスタムリソースのAPIバージョンを入れます。
- ChaosMeshであれば今は、
chaos-mesh.org/v1alpha1です。
- Kubernetes Kind
- 作成するカスタムリソースを入れます。今回は
NetworkChaosを作成します。
- 作成するカスタムリソースを入れます。今回は
- Kubernetes Namespace
- カスタムリソースを作成する名前空間を指定します。今回は
defaultにしました。 先の例でもあったように、これはアプリケーションの名前空間と一致している必要はありません。
- カスタムリソースを作成する名前空間を指定します。今回は
- Kubernetes Spec
- 先述の通り、カスタムリソースのSpec部分をJSON形式で入れます。
今回は以下のようなspecで定義しました。
これは、 sock-shop 名前空間の name:carts のラベルのPodに対して
180秒間の間、90msのネットワーク遅延をおこします。
これにより特定のサービスで処理遅延が発生した場合に、 どのサービスに影響があるかを実験することができます。
{
"action": "delay",
"delay": {
"latency": "90ms"
},
"duration": "180s",
"mode": "one",
"selector": {
"labelSelectors": {
"name": "carts"
},
"namespaces": [
"sock-shop"
]
}
}
ちなみに、普段yamlで定義を書いている人にとっては、いきなりjsonで書けといわれてもちょっと面倒かと思います。
その場合は、yamlを用意しておけば、 kubectl の dry-run 機能を使うことでyamlをjsonに変換することが可能です。
$ cat <<EOF | kubectl create --dry-run=client -o json -f -
apiVersion: chaos-mesh.org/v1alpha1
kind: NetworkChaos
metadata:
name: network-delay
spec:
action: delay
mode: one
selector:
namespaces:
- sock-shop
labelSelectors:
name: carts
delay:
latency: 90ms
duration: 10s
EOF
{
"apiVersion": "chaos-mesh.org/v1alpha1",
"kind": "NetworkChaos",
"metadata": {
"name": "network-delay",
"namespace": "default"
},
"spec": {
"action": "delay",
"delay": {
"latency": "90ms"
},
"duration": "10s",
"mode": "one",
"selector": {
"labelSelectors": {
"name": "carts"
},
"namespaces": [
"sock-shop"
]
}
}
}
残りの実験テンプレートの設定項目については、
ここまで準備していればプルダウンでEKSクラスタを設定したり、
IAMロールの設定で my-fis-role の設定ができると思います。
また、FISの最大の特徴としてCloudWatchと連携して、 実験により想定外の事象が発生した場合には実験を停止させることが可能ですが、 今回は本設定は省略します。
実験をおこなう
ここまで非常に長くセットアップをおこなってきましたが、 ついに実験をおこなうことができます。
実験をおこなう際には、まずは今回の実験に対してどのように振る舞うか仮説を立てましょう。 そして、実験を通して実際の動きと仮説のギャップをみて、 システムの改善ポイントを発見していきます。
今回はデモアプリケーションで、あまり中身の動きはわかっていないのですが、 例えば「cartsアプリケーションにネットワーク遅延が発生することで、 当該サービスは当然レイテンシが大きくなってしまうが、他のサービスには影響は出ないはず」 という仮説を立てたとします。
それではFISの画面から実験を開始してみましょう。
実験を開始すると、うまく動いていれば先ほど定義したとおり、 default 名前空間に対して
NetworkChaos のカスタムリソースが作成されていることが確認できます。
詳細を見てみても、定義したとおりの障害が注入されていることが確認できますね。
$ kubectl get networkchaos
NAME ACTION DURATION
fis-6ph6ccpl6or3ce1l65i36ohj68sjcdr16co3adb474oj6ohl6ssiqthi delay 180s
$ kubectl describe networkchaos
Name: fis-6ph6ccpl6or3ce1l65i36ohj68sjcdr16co3adb474oj6ohl6ssiqthi
Namespace: default
Labels: <none>
Annotations: <none>
API Version: chaos-mesh.org/v1alpha1
Kind: NetworkChaos
Metadata:
(中略)
Spec:
Action: delay
Delay:
Correlation: 0
Jitter: 0ms
Latency: 90ms
Direction: to
Duration: 180s
Mode: one
Selector:
Label Selectors:
Name: carts
Namespaces:
sock-shop
Status:
Conditions:
Status: True
Type: Selected
Status: True
Type: AllInjected
Status: False
Type: AllRecovered
Status: False
Type: Paused
Experiment:
Container Records:
Events:
Operation: Apply
Timestamp: 2022-12-18T04:13:50Z
Type: Succeeded
Id: sock-shop/carts-7bbf9dc945-lb4vp
Injected Count: 1
Phase: Injected
Recovered Count: 0
Selector Key: .
Desired Phase: Run
Instances:
sock-shop/carts-7bbf9dc945-lb4vp: 1
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal FinalizerInited 27s initFinalizers Finalizer has been inited
Normal Updated 27s initFinalizers Successfully update finalizer of resource
Normal Started 27s desiredphase Experiment has started
Normal Updated 27s desiredphase Successfully update desiredPhase of resource
Normal Updated 27s records Successfully update records of resource
Normal Applied 27s records Successfully apply chaos for sock-shop/carts-7bbf9dc945-lb4vp
Normal Updated 27s records Successfully update records of resource
そして、実験が終わると自動的にカスタムリソースが削除されて実験前の状態に戻ったことがイベントからも確認できます。
$ kubectl get event
(前略)
4m31s Normal Started networkchaos/fis-6ph6ccpl6or3ce1l65i36ohj68sjcdr16co3adb474oj6ohl6ssiqthi Experiment has started
4m31s Normal Updated networkchaos/fis-6ph6ccpl6or3ce1l65i36ohj68sjcdr16co3adb474oj6ohl6ssiqthi Successfully update desiredPhase of resource
4m31s Normal Updated networkchaos/fis-6ph6ccpl6or3ce1l65i36ohj68sjcdr16co3adb474oj6ohl6ssiqthi Successfully update records of resource
4m31s Normal Applied networkchaos/fis-6ph6ccpl6or3ce1l65i36ohj68sjcdr16co3adb474oj6ohl6ssiqthi Successfully apply chaos for sock-shop/carts-7bbf9dc945-lb4vp
4m31s Normal Updated networkchaos/fis-6ph6ccpl6or3ce1l65i36ohj68sjcdr16co3adb474oj6ohl6ssiqthi Successfully update records of resource
91s Normal TimeUp networkchaos/fis-6ph6ccpl6or3ce1l65i36ohj68sjcdr16co3adb474oj6ohl6ssiqthi Time up according to the duration
91s Normal Updated networkchaos/fis-6ph6ccpl6or3ce1l65i36ohj68sjcdr16co3adb474oj6ohl6ssiqthi Successfully update desiredPhase of resource
91s Normal Updated networkchaos/fis-6ph6ccpl6or3ce1l65i36ohj68sjcdr16co3adb474oj6ohl6ssiqthi Successfully update records of resource
91s Normal Recovered networkchaos/fis-6ph6ccpl6or3ce1l65i36ohj68sjcdr16co3adb474oj6ohl6ssiqthi Successfully recover chaos for sock-shop/carts-7bbf9dc945-lb4vp
91s Normal Updated networkchaos/fis-6ph6ccpl6or3ce1l65i36ohj68sjcdr16co3adb474oj6ohl6ssiqthi Successfully update records of resource
72s Normal FinalizerInited networkchaos/fis-6ph6ccpl6or3ce1l65i36ohj68sjcdr16co3adb474oj6ohl6ssiqthi Finalizer has been removed
72s Normal Updated networkchaos/fis-6ph6ccpl6or3ce1l65i36ohj68sjcdr16co3adb474oj6ohl6ssiqthi Successfully update finalizer of resource
さて、実験の結果はどうだったでしょうか。 改めてGrafanaの画面を見てみます。
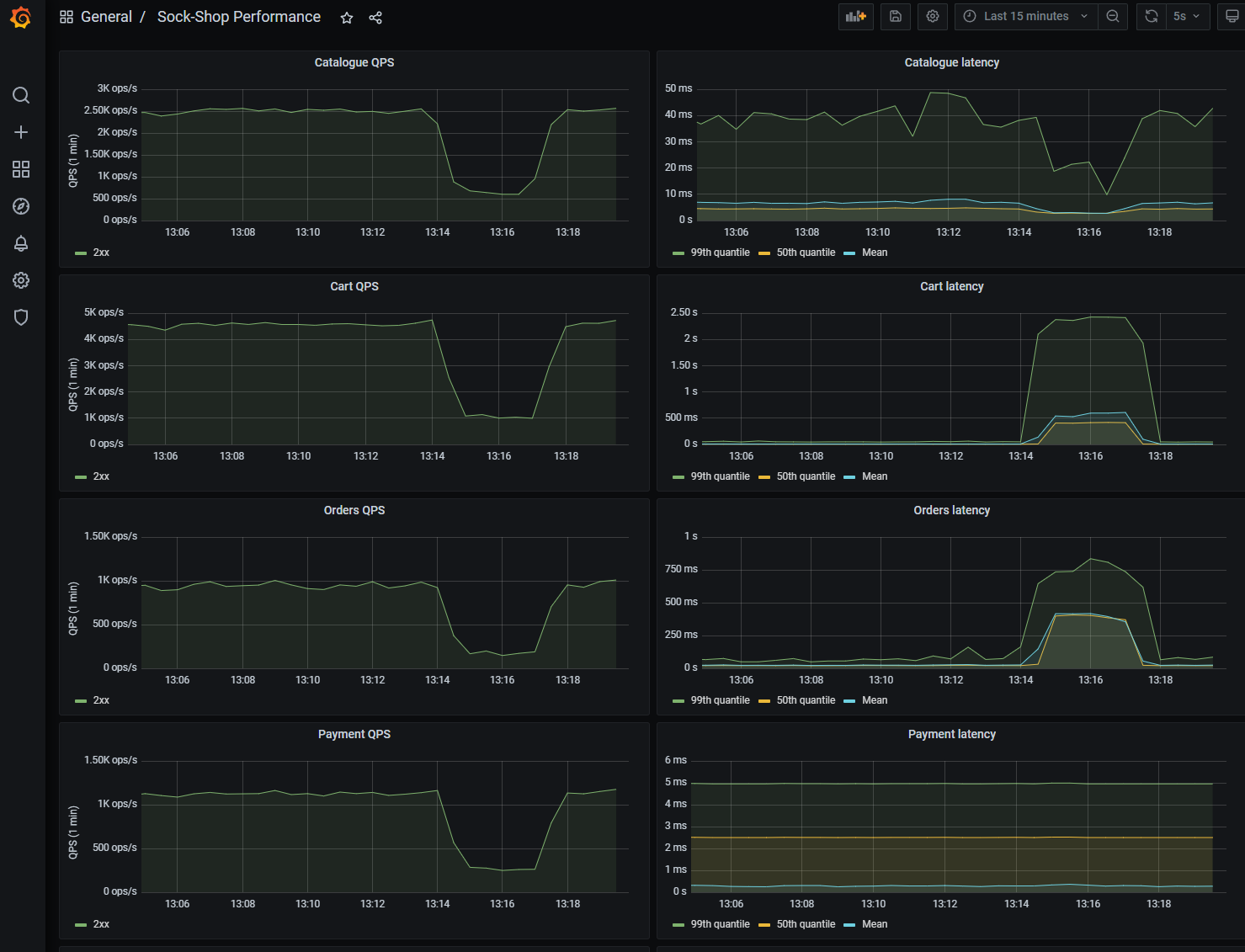
Cartのレイテンシ(2行目右側)のグラフから実験中はレイテンシが非常に大きくなっていることが確認できます。 さらに、Orders(3行目右側)についてもレイテンシが同様に大きくなったことが確認できました。 その一方で、CatalogueやPaymentについては、そこまで影響は受けていないように見えます。
このように仮説と実際の挙動が異なる箇所については、万が一障害が発生した場合に 予期せぬ事象につながったり、修復に時間がかかったりとサービス影響が出やすいところと言えます。
カオスエンジニアリングを実施することで、この仮説と異なる部分を見つけだし改善したり、 逆に仮説通りであることを確認することで、システムの信頼性を高めることができます。
まとめ
今回は、FISとChaosMeshの連携を実際に試してみました。 正直な感想としては、セットアップに時間がかかり、FISでの設定もあまり親切でないところから わざわざFISから呼び出さなくてもChaosMesh単体で使えばよいかな、と思いましたが、 FISにはCloudWatchと連携して実験が予期しない動作をした場合に止めるなど優れているところも多くあります。
今は、まずはFISで実施できるアクションを増やしてみた、という段階だと思いますので、 これからよりマネージドに便利に扱えるようになることに期待したいと思います。
Share